
Spesso è più facile comprendere i casi d'uso per i database a grafo che capire come funzionano i database a grafo. Ad esempio, porsi la domanda su chi siano i leader di pensiero più potenti su più social network, con la più grande varietà di connessioni, siano più adatti per i database a grafo perché l'alternativa di eseguire la query in un database relazionale richiederebbe un numero ridicolo di join di tabella .
E così, con TigerGraph che ha avviato la ricerca e sviluppo di prodotti da una nuova base di San Diego e ha nominato un nuovo capo dell'operazione, il Dr. Jay Yu, ha fornito la scusa per guardare la traiettoria per l'azienda, per non parlare della nostra lista dei desideri per i database a grafo, che è tutta una questione di semplificazione.
Impostare il contesto
I database grafici sono tutti intorno a noi, ma il più delle volte si nascondono in vista del piano. Un buon esempio è Microsoft Graph, che Microsoft caratterizza come “il gateway per i dati e l'intelligence in Microsoft 365”. Più precisamente, può essere usato per orchestrare il flusso di documenti, attività, messaggi o altri processi in Microsoft 365, che ovviamente comprende Microsoft Office. Ma per gli sviluppatori, Microsoft Graph è esposto come un'API su cui scrivere app, non un database. In questo caso, Microsoft modella tutti i dati, gli sviluppatori possono semplicemente eseguirli e giocarci.
Ma sempre più spesso, i database a grafo stanno perdendo i loro travestimenti perché i casi d'uso ci stanno solo guardando negli occhi. Possono spaziare dal tracciamento delle minacce alla sicurezza informatica alla gestione del rischio nei servizi finanziari, alla lotta al riciclaggio di denaro sporco, ai motori di raccomandazione, al supporto del giornalismo investigativo, alla fornitura di raccomandazioni per i trattamenti sanitari in tempo reale, alla creazione di grafici di conoscenza per l'esplorazione dello spazio. Il filo conduttore è che l'estrazione di saggezza implica il pettinatura attraverso molteplici reti di relazioni.
Dove andare da qui? Qualche settimana fa, George Anadiotis in queste pagine ha sostenuto che i database a grafo costituiscono un trampolino di lancio logico per l'IA. Lo esamineremo dal basso verso l'alto: i database a grafo devono disegnare una base di competenze di massa critica e diventare più accessibili, sia per gli sviluppatori che per gli analisti aziendali.
Si inizia con i linguaggi di query
La sfida con i database grafici è costruire quella base di competenze. A differenza del relazionale, non ha 40 anni di storia in azienda e un linguaggio di query comune, SQL, attorno al quale disegnare una base di competenze. E a differenza dei database di documenti, i database di grafici non hanno sfruttato un'abilità già comune con gli sviluppatori (ad esempio JavaScript) con i loro costrutti di dati JSON. E tra l'altro, i database a grafo richiedono un approccio diverso alla modellazione dei dati; non c'è nemmeno una ricca riserva di esperienze.
Ma lo sviluppo che ha impedito ai database grafici di diventare una nota a piè di pagina in db-Engines è stata l'invenzione del grafico delle proprietà, che è diventato popolare dai fondatori di Neo4J. Prima di allora, i grafici erano una conseguenza dell'iniziativa del W3C Semantic Web, che richiedeva triple RDF abbastanza rigide. Con le triple, ogni nodo doveva portare un soggetto, un predicato e un grafico. Sebbene tali modelli siano adatti per corpus di informazioni ben delimitati e ben definiti, come la ricerca farmaceutica clinica, i grafici delle proprietà (o più specificamente, “grafici delle proprietà etichettati”) che definiscono il mondo come nodi (entità) e collegamenti (relazioni ) si è rivelato molto più flessibile e più facile da modellare. Nel suo pezzo, Anadiotis ha parlato di RDF**, che potrebbe fornire quell'inafferrabile collegamento logico tra RDF e grafici di proprietà.
Il prossimo ostacolo è il linguaggio di query. Fino a poco tempo fa, ogni provider di database a grafi aveva un proprio linguaggio unico, il che significa che non c'era un obiettivo comune per costruire una base di competenze di massa critica. Alcuni dialetti popolari, a partire da Gremlin come linguaggio procedurale, uscito dal progetto Apache TinkerPop, hanno fornito una sintassi per navigare in un database a grafi. Alcuni provider stanno formando le proprie alleanze, come Neo4J e AWS attorno a OpenCypher, l'implementazione open source del linguaggio di query Cypher di Neo4J.
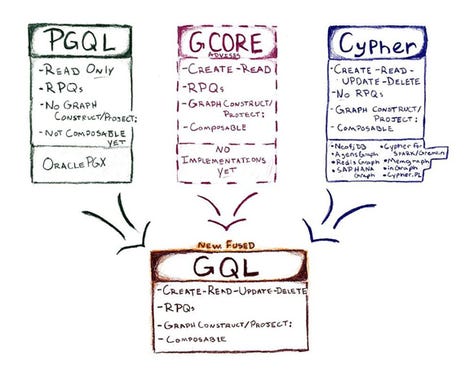
Le radici di GQL
Credit: The GQL Manifesto
Ma ci sono alcuni segni di sanità mentale emergente, poiché giocatori come Neo4J, TigerGraph, Oracle e altri stanno collaborando a GQL. Ora un progetto ISO ufficiale, GQL è stato progettato come un linguaggio dichiarativo che fonderebbe elementi di Cypher di Neo4J; PGQL di Oracle; e GCore, un'implementazione di riferimento. Alla fine della giornata, non ci aspetteremo che Neo4J rilasci Cypher, né TigerGraph lascerà cadere il suo GSQL più simile a SQL. Prevediamo che GQL sarà un'implementazione di riferimento rispetto alla quale i linguaggi dei fornitori aggiungerebbero compatibilità incrociata e quindi si avvicinerebbero all'obiettivo di avere un obiettivo di competenze comune.
Vai dove vivono sviluppatori e analisti aziendali
h3>
Andiamo al sodo: rendere il grafico più accessibile agli sviluppatori e agli analisti aziendali è stato l'argomento di cui abbiamo parlato con Drs. Yu e Xu di TigerGraph circa. TigerGraph, che ha raccolto $ 171 milioni in finanziamenti di rischio, non è così noto come il suo principale rivale Neo4J. Ma TigerGraph si è differenziato con il supporto per un'architettura di database distribuita che impiega una serie di trucchi, come la compressione dei dati, il partizionamento automatico, la pre-compilazione di query per semplificare gli attraversamenti e l'aggregazione di risultati intermedi. Per eseguire un'attività simile, altri database a grafo richiederebbero la suddivisione dei dati e l'elaborazione in più istanze fisiche separate con i risultati uniti. In un recente comunicato stampa, la società ha citato un cliente simile a Uber nel sud-est asiatico che ha scambiato TigerGraph dopo che Neo4j non è riuscito a scalare.
L'azienda ha fatto alcune mosse per rendere i dati più accessibili. Ad esempio, offre uno strumento di trascinamento della selezione per lo sviluppo di query e dispone di connettori per Power BI e Tableau, che sono onnipresenti nel mondo della visualizzazione della BI. È praticamente una posta in gioco poiché la maggior parte delle piattaforme grafiche popolari ha connettori BI. Naturalmente, se il tuo team ha competenze con i database relazionali o NoSQL, molte di queste piattaforme offrono viste materializzate di grafici che ti consentono di eseguire query di grafici abbastanza semplici in grado di gestire, al massimo, 2-3 attraversamenti (insiemi di relazioni). Ma per le query più complesse, come la scoperta di modelli di frode o furto di identità, sarà necessario un database che rappresenti i dati in modo nativo nello schema grafico.
Con il centro di ricerca e sviluppo dell'azienda a San Diego e l'esecutivo principale in atto, abbiamo chiesto quale sarà il prossimo obiettivo della loro agenda. In cima alla lista c'è l'aggiunta del supporto per nuovi linguaggi e API, andando dove vivono gli sviluppatori (e non necessariamente gli sviluppatori di database grafici). Stanno aggiungendo il supporto per GraphQL, un'API combinata e un linguaggio di query che è molto più efficiente di REST quando si tratta di semplici recuperi di dati. Sebbene abbia “graph” nel suo nome, GraphQL non è stato associato a database a grafo fino ad ora. Invece, il grafico in GraphQL si riferisce al grafico della conoscenza sottostante che mappa l'origine dati, quindi fornisce scorciatoie per ottenere i dati giusti senza tutte le chiacchiere di una chiamata RESTful.
Non sorprende che GraphQL si sia dimostrato popolare con le app mobili e abbia creato punti d'appoggio con database NoSQL come MongoDB o Apache Cassandra. La popolarità di GraphQL è diventata virale tra gli sviluppatori al punto che una nuova società, Hasura, ha costruito attorno ad esso un servizio cloud per eseguire query su PostgreSQL, come abbiamo recensito circa un anno fa. Ed è a quel crescente grado di familiarità tra gli sviluppatori di dispositivi mobili che TigerGraph sta cercando di attingere per diffondere la propria impronta.
Un altro pezzo del puzzle per incontrare gli sviluppatori sul proprio territorio è completare le connessioni a tutti i principali motori di calcolo e archivi di dati, come Apache Spark e Cassandra. La nostra opinione è che ciò potrebbe portare all'aggiunta della virtualizzazione dei dati, in cui TigerGraph potrebbe accedere ai dati in fonti come Cassandra, MySQL, PostgreSQL o altri nella top ten di db-Engines, trattandoli come nodi estesi e bordi. Quando si tratta di proiettare visualizzazioni di grafici su dati non grafici, perché Cassandra o MongoDB dovrebbero prendersi tutto il divertimento?
Abbiamo qualche altro elemento nella nostra lista dei desideri. Per cominciare, strumenti che possono aiutare gli sviluppatori alle prime armi a creare grafici con strumenti di modellazione, in modo che possano capire come strutturare le reti di relazioni che sono fondamentali per rappresentare graficamente lo schema del database.
Ma non dimentichiamo gli utenti business. Fornire collegamenti agli strumenti di BI sono i primi passi ovvi, ma sfornare visualizzazioni basate su viste relazionali non renderà giustizia a spiegare le sfumature dei diversi livelli di relazioni che forniscono le risposte reali alle loro domande. Tuttavia, non dovremmo richiedere agli utenti finali aziendali di formare query basate sulla rete di connessioni tra i diversi vertici.
L'idea corrente è che, mentre gli utenti aziendali potrebbero non avere la più pallida idea di cosa sia un database grafico o di come interrogarlo, le domande che pongono sono abbastanza semplici: chi sono gli influencer più importanti? Chi sono i pazienti comuni su più reti di riferimento? Come distinguere rapidamente i siti Web sicuri da quelli dannosi per proteggere la sicurezza informatica? Come prevenire l'abbandono degli spettatori analizzando i loro modelli di consumo di intrattenimento in streaming? Oppure, come identificare i modelli di riciclaggio di denaro analizzando le connessioni tra diverse indagini? Questo è un passo un po' ambizioso, ma quando stiamo già vedendo apparire query in linguaggio naturale negli strumenti analitici, non è un salto di concetto applicarlo ai dati connessi all'interno dei database a grafo.
Big Data
Dov'è il launchpad del cloud ibrido di IBM? Sette modi per rendere la tecnologia in tempo reale reale per la tua organizzazione Machine learning all'avanguardia: TinyML sta diventando grande Quali sono le prospettive di Cloudera? McDonald's vuole “democratizzare” l'apprendimento automatico per tutti gli utenti nelle sue operazioni
Argomenti correlati:
Gestione dei dati Trasformazione digitale Robotica Internet delle cose Innovazione Software aziendale ![]()