Fotografier fra et historisk øjeblik i teknologinyhedshistorien, den dag en Gizmodo-reporter offentliggjorde praktiske billeder af den dengang endnu ikke annoncerede iPhone 4, mangler nu. Og de er ikke alene – enorme mængder af billeder fra G/O Media-websteder som The Onion, Jalopnik og Deadspin (såvel som Gizmodo) er blevet fjernet, angiveligt med vilje, ifølge Gawker.
En nylig Gawker-rapport fremhæver, at Buzzfeed også har slettet mange ældre billeder fra nettet. Alligevel er Buzzfeeds grund til at gøre det relativt tydelig, efter at ledelsen forklarede, at ophavsretskravene på gamle billeder anså nogle af dem for “højrisiko”.
Begge tilfælde er eksempler på “link rot”, hvor indhold på internettet ændres drastisk, fordi det enten forsvinder helt, eller fordi væsentlige dele er forsvundet.
Linkrot rammer en skelsættende historie i teknologinyhedshistorien
Som et crashhistoriekursus var en prototype af iPhone 4, der endte i hænderne på tech-journalister, en kæmpe aftale i 2010, og et nøgleelement i øjeblikket var billederne. Folk nåede at se telefonens helt nye design og dens interne komponenter, før Steve Jobs overhovedet kunne komme på scenen og annoncere det. Det blev til en fiasko, der involverede politiets razziaer i en redaktørs hjem (alle de juridiske dokumenter, som Gizmodo postede i den artikel, er i øvrigt væk), men nu er disse billeder fanget i deres eget drama.
G/O Media-medarbejdere har tilsyneladende ikke fået en grund til, hvorfor billederne og kunstværket er forsvundet fra deres artikler, og virksomhedens ledere har angiveligt ikke advaret dem om, at det ville ske. Gawker spekulerer i, at det kan skyldes ophavsretlige bekymringer, og citerer sin rapport om Buzzfeed, der gør det samme.

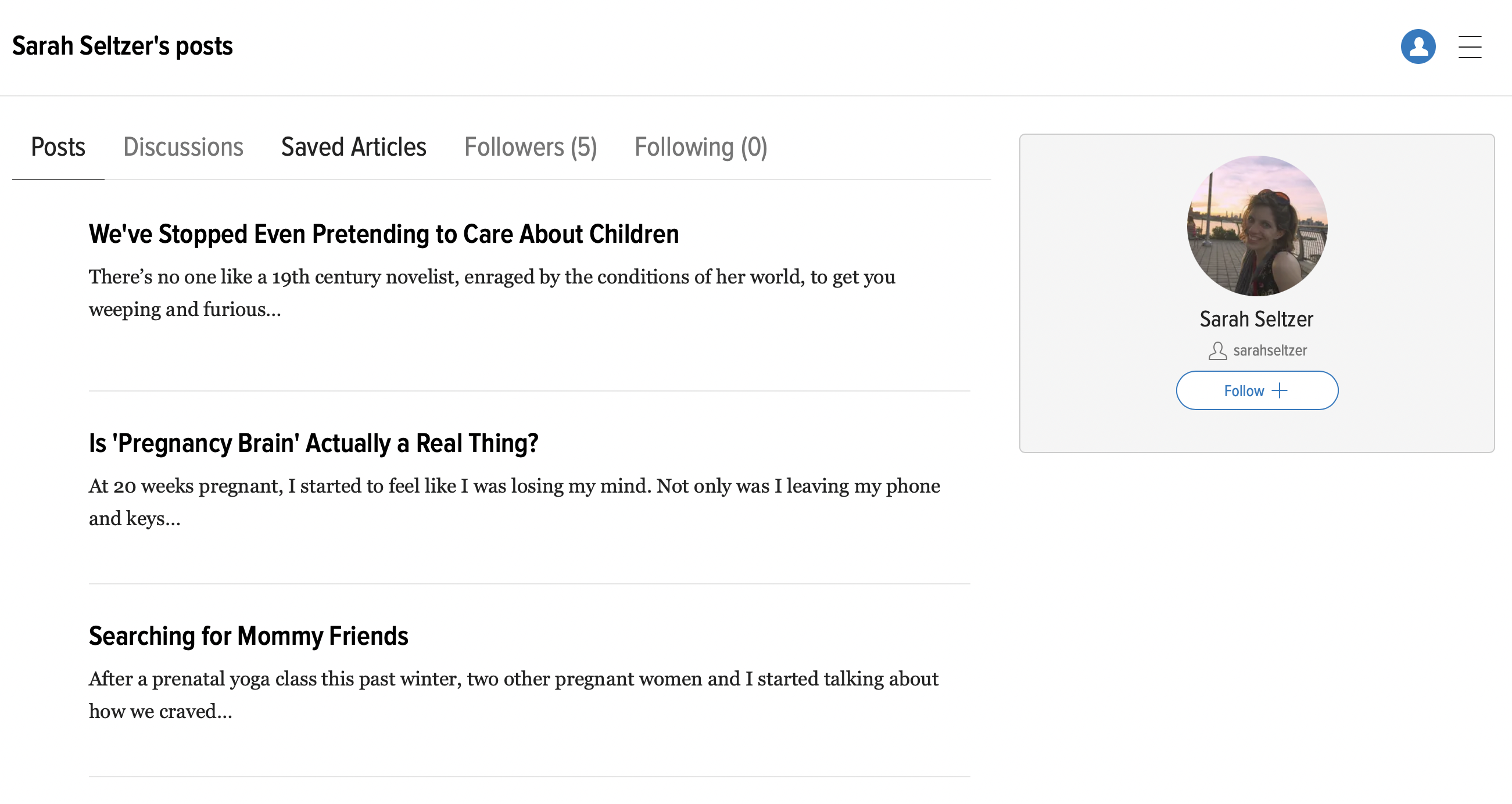 Venstre: en forfatterside med seneste artikler, til højre: en forfatterside med artikler fra 2017
Venstre: en forfatterside med seneste artikler, til højre: en forfatterside med artikler fra 2017
Der er også nogle interessante tidspunkter vedrørende webstedernes ejerskab, som kan påvirke ophavsretten på andre måder. Gawker rapporterer, at billederne, der blev fjernet, ser ud til at være fra artikler, der blev offentliggjort på webstederne, før de blev en del af G/O Media. Før de blev købt af deres nuværende ejer, et private equity-firma, havde mange af webstederne været en del af Gizmodo Media. Denne enhed sprang ud af asken fra Gawker Media (af en vis relation til den nye Gawker-rapportering om dette). For at gøre en lang og kompliceret historie kort, så er de berørte artikler tilsyneladende forud for virksomhedens stærkt kritiserede-indefra nuværende ejere.
G/O Media reagerede ikke umiddelbart på en anmodning til kommentar.
Med så meget indhold væk, har nogen sikkert mistet noget, de elskede
Uanset årsagerne til, at det sker, har forsvinden af så meget internethistorie tydeligvis rørt en nerve. Verge-alumen Bryan Menegus påpegede på Twitter, at en Gizmodo-artikel, der viser en Amazon-antiforeningsvideo, mangler sine vitale billeder. En anden Twitter-bruger påpeger, at en Kotaku-artikel om vildtbevarelse (ironisk nok) nu mangler sin kunst. Der er også andre eksempler: Utallige antal af Onion-artikler, der har fået deres vittigheder ødelagt, en Verge-kollega påpegede, at sjældne billeder af et nedlagt kraftværk, vi engang havde beundret, nu er væk, og tidligere anmeldere har talt om, hvordan indsatsen de lægger i at tage billeder nu synes spildt.
:no_updnvo.com/cddnvo/cdn /chorus_asset/file/22961111/Screen_Shot_2021_10_27_at_15.53.25.png "Gizmodo's billeder fra den massive iPhone 4-lækage er forsvundet") Selv forhåndsvisningen er blot en tom, hvid firkant. Twitter: @bryanmenegus
Selv forhåndsvisningen er blot en tom, hvid firkant. Twitter: @bryanmenegus :no_updnvo.com/cdnload.com/cdnload.com//chorus_asset/file/22961115/Screen_Shot_2021_10_27_at_15.55.50.png "Gizmodo’s billeder fra den massive iPhone 4-lækage er forsvundet") Twitter: @transgamerthink
Twitter: @transgamerthink Vi har set massive tilfælde af linkråd før, med et bemærkelsesværdigt eksempel fra, hvad der skete, da Twitter forbød daværende præsident Donald Trump – nyhedsartikler, der indlejrede hans tweets som kontekst eller bevis, viste pludselig næsten tomme kasser i stedet for.
En nylig undersøgelse viste, at en fjerdedel af de “dybe links” (eller links til specifikke sider) i New York Times' digitale artikler ikke længere fører til det indhold, de skulle. I mange tilfælde er forklaringerne ikke dramatiske: En side kan have ændret webadresser eller blevet slettet, eller et websted kunne være gået ned, fordi ingen gad at fortsætte med at arbejde på det. Der har været tilfælde, hvor svindlere bevidst kaprede døde links for at få intetanende klik, men ofte er det bare et tilfælde af internetentropi. Slutresultatet er dog det samme – det indholdslæsere engang vidste ikke længere var tilgængeligt.
Internettet ændrer sig konstant, på godt og ondt
Link råd kan være almindeligt, men det er stadig et massivt problem, hvis vi skal bruge internettet som et globalt lager af viden. Hvis du henter et blad for 50 år siden og læser det, får du mere eller mindre nøjagtig samme oplevelse som en, der købte det, den dag det blev udgivet. Gør det samme med en internetartikel fra et par år siden, og så kaster du terningerne.
Der har været tappere bestræbelser fra folk som Internet Archive for at forsøge at gemme stykker internethistorie (og faktisk kan du stadig læse iPhone 4-artiklen med billeder intakte på gruppens WayBack Machine efter at have jagtet artiklens originale URL), men der er kun så meget, som enkelte organisationer kan gøre. Vigtige ting vil falde igennem, medmindre noget grundlæggende ved nettet ændrer sig, eller virksomheder tager bevarelse alvorligt.